第二期培训课程
参考:许逸民《古籍整理释例》
0课程简介
利用识典古籍平台来整理古籍,高效,
整理的全流程
掌握背后的基本原理,不是简单的如何使用平台的方法
- 【转线下修改】智能古籍整理平台(为什么要用智能整理平台来整理古籍)
- 整理平台的优点
这是一个什么样的平台?
识典古籍整理平台是一个充分利用人工智能技术、计算机技术来进行古籍整理的集成平台。很多老师肯定会说,我用传统整理的方法就挺好的,为什么要费心费力来学习如何用整理平台来整理古籍呢?答案是,利用平台确实有很多益处。多、快、好、省,除了“好”之外,“多”、“快”、“省”确实能够做到。利用平台,可以大大减轻整理者的工作量,花更少的时间,能够整理更多的内容。
这个平台能干什么?
识典古籍整理平台是一个全流程的整理平台,只要你有古籍图像,上传到平台之后,就可以通过人机协作的方式,一步步完成文字识别、校勘、结构整理、标点等古籍整理的核心环节,此外还有古文的现代等翻译功能。
虽然这个整理平台能够在古籍整理的大部分环节中都帮上忙,但并不是所有涉及古籍整理的内容都可以利用。比如古籍的选目工作,古籍图像的获取,底本与校本的选取,这些都不能在平台上进行。另外,古籍的注音与释义的功能还没有加入进来。
适合整理哪些古籍?不适合哪些古籍整理?
传统的古籍整理范围很广,不是所有的古籍整理都可以在平台上进行。该平台特别适合按照古籍原貌进行整理,从古籍书影开始,整理的结果与图像保持一致。如果要对古籍进行选编、改编、重编、辑佚等,平台不是不可以有帮助,但可能在数据准备上就比较麻烦些。如果要对某一版本的古籍进行整理,那么一开始就有必要利用目录学、版本学知识选定适合进行整理的古籍。
整理平台主要针对传统古籍整理的哪些痛点?
古籍整理是很机械的一项工作,有很多环节都非常的耗时耗力。利用平台上的人工智能技术,可以大大对这些耗时耗力的环节进行提效。
1、文字录入慢。有了影印技术之后,古籍整理往往在底本的复印件上进行,将标点、校勘写在影印件上。这样的稿子,最终需要出版社进行录入工作。现在一些年轻的整理者,更习惯在电子文本上进行整理。如果能在网络上找到与底本接近的文本还好,找不到的话,很多整理者选择自己录入。如果不是专业的打字录入,古籍的录入速度会很慢,古籍中有大量不常用的字,用拼音录入会有很多不知道怎么读,纵然知道怎么读,也要翻很多页才能找到,如果用手写录入生僻字,输入法来回切换烦不胜烦。我就有朋友,为了整理一本古籍,几十万字的内容,先花了两年的时间录入了一遍,后面还有用电脑与古籍图像校对好几遍。
2、标点速度慢,容易出错。很多古代文学、古代哲学、古代历史的硕博考试会有古文加标点、翻译。说明这是进入古代世界的基本技能。绝大部分古籍原书都是没有句读的,如果阅读没有整理过的古籍,首先就需要进行句读。如果句读不对,往往会遭到别人的质疑,肯定没有理解古籍的意义。人工加标点,速度比阅读慢很多,而且标点很机械,长时间加标点人很容易疲惫,从而造成错误。要达到一定精度,需要反复审阅数遍,才能保证一定的质量。标点错误往往很难发现,很容易忽略而过。遇到疑问,往往还需要查询很多文献才能解决。
3、校勘速度慢,容易漏校。校勘说简单很简单,说复杂又很复杂。说简单,其实就是机械的比较两个版本的差异,特别是汇校,把所有差异一一列出,不做判断。如果两个版本相似度高,差异不很大,比如1000个字,有1-2处不同,这种容易不少。当然看似简单,比出差异,还要看,是不是真的不同,是不是异体字。说复杂,校勘很难,需要具有丰富的文字学知识,特别是如果校勘原则中可以改字的话,则需要非常谨慎,在读懂上下文基础上综合判断。传统的校勘中,参校还好,如果是对校,很容易有漏校。如果有漏校,需要重新校对一遍,每校对一遍,都需要耗费大量时间。特别是部头很大的情况下,校对能校对到怀疑人生。
4、加专名线速度慢,容易出错。很多古籍整理,会有专名的标识。如果有专名线(人名、地名、时间等),就会大大方便读者的阅读。但是对于整理者来说,确实非常艰辛的一项工作。特别是对于历史类典籍,加专名线非常机械,而且加了之后,还容易出错。
平台针对这些传统古籍整理的痛点都有哪些环节的设计?
1、针对录入,借助OCR技术,可以大大节约录入的时间成本。目前OCR技术在版刻古籍上能够达到很高的准确率,只要图像足够清晰,版面不是特别复杂,都可以有很好的识别效果。
2、针对标点,有自动标点技术。利用先进的自然语言处理技术,自动标点已经能达到专家学者的水平。
3、针对校勘,有自动校对技术。计算机算法可以辅助将文本的差异标识出来,节约校对的时间成本。
4、针对专名线标识,有命名实体识别技术。命名实体识别可以快捷地将古籍中的人名、地名、时间等识别出来,达到较高的准确率。
整理平台有哪些优点?
1、人机协作,充分发挥人工智能的力量。实践表明,古籍OCR、自动标点、命名实体识别这三项人工智能技术可以大大减轻古籍中繁琐的工作。但是人工智能还不能完全脱离人进行古籍整理。版式清晰的古籍OCR的正确率能达到95%,甚至更高,但还有不少字需要人工校对才能正确。版式如果复杂,图像不是特别清楚,可能还需要较多的人力才行。自动标点的准确率较高,能够弥补人的一些不足,但是仍然会有一些错误,特别是在缺字、异字体等地方会有一些不准确的地方。因此最好是先进行机器的初步处理,然后再借助人工的校对。每一个较大的环节都这样进行,通过人机的协作,逐步提高质量。
2、人与人的分工。文字识别、文字校对的工作很机械,经过一定培训的大学生就可以胜任,因此专家学者可以聚焦于其中比较困难的地方,需要专业知识才能认识的地方。标点会困难一些,专家学者可以将更多的力气用在标点上。利用一定的技术,甚至专家学者只针对其中疑难的标点进行处理,一般的审订交给研究生。校勘也可以如此。
3、古籍整理门槛相对降低。传统的古籍整理非常考验一个人古籍阅读的能力,如果没有一定的文字学知识,古代汉语水平,完全没有办法整理古籍。所以传统的古籍整理最好是专门研究某一领域的专家进行。但是借助古籍整理平台,文字识别、标点都可以有人工智能技术、计算机技术进行辅助,特别是一些不那么复杂的古籍,大众完全可以参与整理。在传统古籍整理当中,哪怕是专业的古籍整理行家,如果不专门研究某一领域,也很容易犯标点的错误。但是自动标点由于建立在所有领域的语料基础上,在各类古籍上都有较好的标点水平。
4、由粗到精,动态更新。传统的古籍整理面向纸质出版,所以需要一个较高的准确率才能出版。但是识典古籍整理平台内容的发布可以是动态的,对于不那么需要精校的古籍,可以快速的利用人机协作的方式整理出一个粗的版本,然后在此基础上,再利用众包等方式逐步打磨,达到更精的水准。
5、比较算法,重点突出。识典古籍整理平台充分利用比较的算法,文字识别、文字校对均可以与已有的数字化成果进行比较;标点校对环节,也可以与已有的整理本标点或者其他自动标点进行比较,更快的锁定可能有误的地方。因此老师们在整理的过程中,一定要注意尽量利用已有的数字化成果或学术成果。
6、整理平台与阅读平台是联动的,打造出下一代的数字图书馆。整理平台相当于厨房,阅读平台相当于餐桌。厨房里加工好的成果,可以快速地端上餐桌。两个平台无缝衔接,是两个平台,又是一个平台。我们一般了解的数字图书馆主要是数字化成果的发布,主要利用数据库技术,实现检索与查看,相当于阅读平台所具有的。但识典古籍平台把数字图书馆的加工平台与数字图书馆联动起来,将传统数字图书馆的内容,特别是古籍图像图书馆的内容进行进一步加工,可以说是下一代的数字图书馆。
- 整理平台的流程设计
很多老师刚使用整理平台,会感觉到平台上功能貌似很多,不知道怎么才能开始整理工作。但实际上设计的思路是很简单清晰的。整个平台贯彻着人机协作的理念,一般环节都是先机器处理,然后再人工处理。
1、首先,建元数据。你想整理哪本古籍,整理哪本古籍更有价值,这都需要老师们利用目录学、版本学知识,结合教学与研究的需要来进行。确定了整理古籍的选目,就需要首先在平台上建立一个书的元数据,输入古籍的题名、作者、年代、版本、分类等这些最基本的信息。
2、其次,数据准备。如果还没有古籍的数字图像,首先各显神通找到古籍的数字图像,目前有很多开放访问的古籍,还有大量影印古籍,都可以作为待整理的图像。目前平台默认支持从图像开始的整理方式,如果已有加工好的图文对照的数据,可以略过文字识别的环节,直接进入文字校对环节或者标点校对环节。为了更好的进行任务分发以及更好的整理体验,强烈建议进行分卷操作。分卷完成,确定好内容,就可以进行整理环节了。
3、然后,开始整理。如果从图像开始,可以走全部的流程,从文字识别、文字校对、文字校勘,然后进行结构整理、标点校对、实体整理。如果需要还可以进行。具体进行哪些环节,可以根据需要选取。比如,版式识别效果较好,可以直接进入文字校对环节。结构整理也可以不单独进行,可以与文字校对或者标点校对一起进行。环节本身有一个固定的顺序,但也可以选择每次只进行一个环节。在书籍的总页面可以看到每一卷当前的流程。
4、最后,发布成果。如果觉得文字、标点这些主要的方面达到一定的质量,就可以选择申请上架,当然不愿意发布的,也可以选择将成果下载下来,进行一些其他的线下处理。
演示:流程页面
作业:注册一个账号,加入团队,任团队管理员
- 【转线下修改】元信息著录(如何在平台上规范地著录一种古籍的身份信息)
在中国古代,我们有着很久远的书籍著录的传统,最早如西汉刘向受命参与校理宫廷藏书,校完书后写一篇简明的书籍提要,后汇编成《别录》。后来如《汉书艺文志》《隋书经籍志》《四库全书总目》,都延续了这样的目录学传统。通过古籍目录,我们可以了解不同时代的书籍状况,也可以“考镜学术,辨章源流”,了解古籍的学术脉络和源流。另外一方面,我们也可以通过目录书去了解每一本书的大致内容,实现按图索骥,按需寻找文献的功能。
我们在识典古籍上的目录采用元信息的方式著录。什么是元信息,实际上就是古籍的身份信息。要开始整理一本古籍,首先要建立一条书籍元信息。最基本的元信息可以主要分为:书名、版本、作者、部类。在平台上,这几项是必填项。元数据一方面用于区别不同的书籍,另一方面也便于更方便进行检索。
需要注意的是,书籍的元信息的著录,我们强烈建议尽量使用标准繁体字,不要有异体字,也不要用简体字。
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。元数据算是一种电子式目录。
值得注意的是,在整理一种古籍的时候,注意检查平台是不是已经有,另外有些书已经在平台的整理计划中,要注意避免重复。
除了以上基本要点以外,识典古籍的元信息大概可以分为以下这几个部分:
- 书名的著录
一般我们要确定一本书,最关键的信息就是书名。
一般来讲,古籍的题名,都位于该书的卷首。如若正文首卷卷端没有题名,或者所题名不能代表全书,应依次从其他各卷卷端、各卷卷末、内封、版心、封面、目录、序跋、凡例等处选择适当的题名作为正题名。必要时可参考《中国古籍总目》https://bibliographical.guji.cn/和其他资料。

其它书名:古籍中的书名是很复杂的,同一部古籍中有很多别名。别名应该放到“其他书名”里。一般来讲书籍名称填写该书的通行名字。很多原书题名若带有冠词,如“新刻”“评点”“钦定”等,应放在其他书名里。
那么到底怎么才算一本书呢?这个其实没有严格的标准。我们建议以“种”为单位。比如有合订本,就是几种书装订在一起,但每一种都可以单独分出来。这种建议拆开,将其中每一种独立出来。还有合编本,就是几种书统一编在一起,比如把《老子》《庄子》《列子》编在一起,有总的序跋,这种书其实可以看作是一种书,当然也可以拆开,共同的序在第一种前,共同的跋在最后一种之后。还有的一种书很小,特别是佛经,会有好几个小经连续抄写在一起,这种虽然每一种经都是单独的,但是在物理上很难分开,可以合并在一起。
对于特殊情况,就要根据实际情况来著录,多个题名全部写在书名当中,中间用顿号隔开。
如果是一套丛书,也建议尽量拆开成每一种。特别是大型丛书非拆不可。小的丛书,能拆分尽量拆分。
- 作者的著录
书名大致能确定某一种书,但是有很多书有重名现象,因此单靠书名并不能唯一确定某一种书。如果加上作者,大致就能唯一确定一本书了。比如《中论》,最有名的可能是鸠摩罗什所翻译,由印度龙树所著。但也有一本东汉徐干所著的《中论》。这两种书,题名相同,但是加上作者,就不会混淆了。因为两种书,一本是印度翻译著作,一本是儒学著作。
作者的著录,可以参考各种目录学著作。分别著录作者的朝代、作者名,还有撰述方式。撰述方式有著、撰、注、编等等,撰述方式有很多,据说有几百种,很多撰述方式之间的差别其实是微弱的,可以按照古籍题写的撰述方式,也可以按照学者考证之后的撰述方式。
值得注意的是,作者可以有多个,一般按照时间顺序,分别著录即可。
若原书未题责任方式,可参考《中国古籍总目》。若未在《中国古籍总目》中找到信息,可参照以下方式选择著录:
撰:著述
修、纂:常用于集体创作书籍的两种责任方式
注:对一部书的内容、文字进行解释
编:将多种著作整理、编排为一种书
辑:收集他人的著述或零散文字,汇集为一种书
译:将一种文字翻译成另一种文字
- 版本的著录(版本学)
版本的著录规范,可以利用版本学的知识,但通常可以查询《中国古籍总目》来解决。这类书目将大部分古籍的版本搜罗其中,对于每一种版本都有版本的名称。特别是常见的馆藏书目或者影印古籍,版本信息都已经有了。只需要照录即可。如果某种书的版本并不常见,可能就需要对版本进行考证了。版本的考证是很专门的学问,这里简单说明一下版本著录的基本内容。
古籍的版本,与现代书籍有相似之处。现代书籍确定某种书,一般会说,哪个出版社哪一年出版第几版。古籍也类似。具体来说,需要尽量指明版本的朝代、出版时间、出版地、出版者、版本类型这些信息。版本名称主要的目的是区分不同版本,并不是越复杂越好。朝代、出版时间、出版地、出版者、版本类型都可以用来区分不同版本。
1、朝代、出版时间,尽可能准确地著录古籍的出版年代。
2、出版地,如果能够明确古籍出版的地点,古代地名应使用当时的称呼,同时可适当注明现代对应地点。例如:“宋临安府刻本”。
3、出版者。如果能够明确刻书机构、书坊名称或私人刻书者。如 “明毛晋汲古阁刻本”,毛晋的汲古阁是著名的私人刻书处。
4、版本类型。版本最后,一般说明版本类型,是写本、抄本、刻本。
5、版本的简称,为了避免繁琐,版本的著录在特定情况下,只保留具有区分度的版本内容。比如某一种书,如果有《四部丛刊》本,可以简称某某书的“四部丛刊本”,具体四部丛刊影印的什么版本,具体查《四部丛刊》的影印目录就可以知道。
对于年代不确定的古籍,可以根据字体风格、纸张材质、避讳情况等进行推测,著录为 “清中期抄本” 或 “约康熙年间刻本” 等模糊表述。
8.2.1 版本说明 版本说明记录古籍的版本类型。本项依据书中有关版本类型的文字记载,并结合版本类型特征 所做的鉴定结论进行著录。 示例1: . -- 稿本 示例2: . -- 寫本 示例3: . -- 抄本 示例4: . -- 彩繪本 示例5: . -- 刻本 示例6: . -- 活字本 示例7: . -- 活字泥版印本 示例8: . -- 磁版印本 示例9: . -- 銅版印本 示例10: . -- 鈐印本 示例11: . -- 石印本 示例12: . -- 影印本 示例13: . -- 鉛印本 原书已经加工者加工成另一著作,应按新著作的版本类型著录,原书情况在附注项说明。 示例 : . -- 稿本 (本書原為清光緒五年楊忱影宋刻本《管子》,清王仁俊據此集注校正成新的著作。) 一种古籍包括多种版本类型时,可选择著录其中主要的两种版本类型,其他版本类型在附注项 说明。 示例1: . -- 刻本暨鉛印本 示例2: . -- 刻本暨鈐印本 示例3: . -- 刻本暨抄本 示例4: . -- 鈐印本暨拓本 示例5: . -- 鉛印本暨石印本 8.2.2 附加版本说明 著录刻本或活字本中以非墨色的彩色颜料印刷、多色颜料或饾版拱花套印而成的书籍时,应依 据单色、双色印刷所用颜色或三色以上套印所用颜色数量的不同,对版本类型作附加说明。若 套印所用颜色数量难以统计,可将附加版本说明著录为“彩色套印”。 示例1: . -- 刻本, 朱印 示例2: . -- 刻本, 藍印 示例3: . -- 刻本, 朱墨套印 示例4: . -- 刻本, 三色套印 示例5: . -- 刻本, 五色套印 示例6: . -- 刻本, 七色套印 示例7: . -- 刻本, 彩色套印 示例8: . -- 刻本, 饾版拱花, 彩色套印 著录活字本应依据制字材料的不同,对版本类型作附加版本说明。 示例1: . -- 活字本, 木活字 示例2: . -- 活字本, 銅活字 示例3: . -- 活字本, 泥活字 著录以某一版本的书籍为底本,用影描方法抄写的抄本、用影摹方法刻印的刻本和用照相制版 的石版、珂罗(玻璃)版和铜版等影印本,均应根据不同情况对版本类型作附加版本说明,并 将其所据底本著录于附注项。 示例1: . -- 抄本, 影抄. -- 江陰 : 繆荃孫藝風堂, 清光緒二十五年 [1899] 據宋臨安尹家書籍鋪刻本影抄) 示例2: . -- 刻本, 影刻. -- 揚州 : 曹寅, 清康熙五十年 [1711] (據宋咸淳元年吳革刻本影刻) 示例3: . -- 影印本, 石版. -- 上海 : 點石齋, 清光緒十九年 [1893] (據清武英殿聚珍本影印) 书中标明的或在抄写刻印过程中形成的版本鉴别特征,可作为版本类型的补充说明扼要著录。 示例 : . -- 刻本, 公文紙印
- 部类的著录(目录学)
目录被认为是“入学之门径”,传统上要找某一种书,按照目录来寻找是很重要的方法。现在目录对于检索功能重要性不那么高了。但是分类浏览的作用还是重要的。识典古籍平台上的分类比较简单。总分为经史子集、道教部、佛教部,与《隋书·经籍志》类似。四部的分类按照《四库全书总目》的分类。道教部则按照《正统道藏》的分类,佛教部则按照《大正藏》的分类。这个分类完备吗?当然不完备,只是说目前差不多能用。这种分类,本身逻辑也不完备,比如四部的子部当中本身有“释家类”、“道家类”,但没有更小的子类。比如四部分类中就没有“新学类”,《正统道藏》的分类也很难对明清之后的道书进行分类。
如果某种书已经收录在《四库全书》、《正统道藏》、《大正藏》中,直接采用对应分类即可。如果属于佛道以外的书,可以查询“经籍指掌”解决。实在找不到合适的分类,可以尽量找一个相近的分类。
- 其他信息的著录
书籍别名:很多书籍有多个名称,“书名”字段可以填写书籍本身的题名,其他方便检索的名称,可以放在书籍别名中。比如有一本书叫《冲虚真经》,书名中可以写“冲虚真经”,那么在别名中则可以写“列子”,作者写“列御寇”。
成书年代:填写学者认为该书的创作年代,这个朝代往往于作者的朝代一致。但也可以不一致,按照学界认可的成书朝代填写。
指数年:指数年英文是Index Year,是用来索引排序的年代。优先是填写成书的公元纪年;如果成书年代不清楚,则填写作者的卒年,因为一般来说,作者去世的时候这本书已经写作出来了,是这本书成书的年代下限。如果作者的卒年不清楚,甚至作者是谁都搞不清楚,那就大致参考书籍出现的年代进行综合判断。如果是公元前,填写负数。
指数年描述:对指数年的数值进行解释,说明为什么采用该指数年的原因。
卷数量:按照古籍正文的卷数填写。
馆藏:可以填写书籍收藏的原图书馆,比如影印古籍、开放访问的古籍,均可以填写,以便溯源。
影印信息,出版社,出版地,出版日期:如果是影印古籍,可以填写有关出版信息。
许可协议:如果是开放访问古籍,可以填写访问链接,以及许可信息。
英译来源:如果英译文本来自互联网,可以填写英译来源信息。
- 书目简介
在当代的古籍整理规范中,也有“点校说明”(或称出版说明、前言、序等)。点校说明包括以下几个部分:
- 作者生平;
- 古籍的内容介绍;
- 版本源流;
- 整理校勘体例
与点校说明类似,识典古籍上也需对该书的内容。
书目简介,要准确、扼要地把古籍的卷数、书籍结构、基本内容、特点、后世影响、学术评价、简要版本情况概括出来。对书籍的评价要采用学术界的主流观点,应当尽可能地客观、准确与平允。读者可以通过这一部分内容快速抓到该书的核心内容与价值。
撰写书目简介,建议优先参考一些现代辞书,比如《四库大辞典》,将《四库全书总目》和《续修四库全书总目提要》的内容精加筛选。撰成一部具有现代气息的大型解题式古籍书目。表述语言用现代汉语。
道教领域如萧登福《正統道藏總目提要》,任继愈、钟肇鹏等《道藏提要》。
佛教领域可参考佛经书目提要劉保金著《中國佛典通論》《佛經解說辭典》鎌田茂雄.《大蔵経全解説大事典》 (雄山閣)、陈士强《大藏经总目提要》。
当然,可以参考古代的《四库全书总目》这样的古代目录书中,就有对每本古籍详尽的提要,对该书进行介绍并进行学术考证。
版本源流
在整理一本书时,最先需考证该书有哪些现存的版本。首先我们需要在《隋书经籍志》《郡斋读书志》《千顷堂书目》等历代目录书中找到该书的著录情况。看看他在古代的卷帙、存亡状况。其次要在《中国古籍总目》《中国丛书综录》全国古籍普查登记平台等查看这些古籍现存的版本。
全国古籍普查登记平台http://202.96.31.78/xlsworkbench/publish?tdsourcetag=s_pcqq_aiomsg
当梳理清楚现存的几个主要版本后,还需进行试校,梳理出该书的版本源流,确定何书为祖本、子本,这些也应该在书籍简介里说明。
整理校勘体例
在确定底本和校本后,要说明该书以xxx本为底本,以xxx本为校本。版本的全称要准确,用影印本的要写明其底本(如《四部丛刊》影印某某本、《续修四库全书》影印某某本;《四库全书》现已有两种影印本,应注明影印文渊阁本或影印文津阁本)。校本要拟定简称,以便写校勘记时使用。简称要简明准确。
“点校说明”,相对于古籍来说,它是一个新的附加物,但绝不是可有可无的。有了“点校聪明”,速者便可以借此了解一部古籍的概貌,包括古籍作者的生平、古籍的基本内容、特点价值、版本流传、整理过程与方式等许多情况。如果没有这样一篇“点校说明”,读者在阅读、使用这部古籍时,肯定会感到诸多不便。有一定目录学知识,懂得古代书目提要、版本题跋重要的人,一定会重视古籍新整理本卷首的“点校说明”。
一、 每本书前都要有一篇 “ 校点说明 ” 。
二、 “ 校点说明 ” 应包括作者生平简介(并括注所依据的主要传记材料)、本书内容价值简介、版本源流简介、确定底本校本的说明,以及其他需要向读者交代的内容。篇幅不宜过长,力求言简意赅。
三、 版本的全称要准确,用影印本的要写明其底本(如《四部丛刊》影印某某本、《续修四库全书》影印某某本;《四库全书》现已有两种影印本,应注明影印文渊阁本或影印文津阁本)。校本要拟定简称,以便写校勘记时使用。简称要简明准确。
四、 对于一位作者有多种着作收入《儒藏》(精华编)者,各书 “ 校点说明 ” 都要写作者生平简介。如其着作在某部类中首次出现,生平简介应相对详细一些;再次出现时,可较为简略。
- 作者简介
作者信息可分为生卒年、字号、籍贯、别名等。我们这里主要介绍作者简介的撰写。
作者简介主要需要说明生平履历。生卒年、字、籍贯、别名等基本信息要在简介里得以体现。还要说明作者的任官履历,以及其生平主要事件。但是这一部分生平履历不能过于冗赘,要抓住相关的要点。此外,还需对其学术思想、主张观点等做简单介绍,此部分需要结合作者的书中内容。最后还需对作者的著作进行概述。
作者简介有很多工具书可以参考,比如《中国人名大词典》,此外还有一些人名数据库、人名辞典可以参考。
知识图谱:https://cnkgraph.com/People
该网站收录12万多名古代诗人、作家的简介信息。收录包括《中国历代人名大辞典》《唐诗大辞典》《列朝诗集》等常用辞书对作者的简介。

法鼓山《佛教人名规范》:https://authority.dila.edu.tw/person/
主要是佛教人物,包括他们的籍贯、大藏经对应的著作信息等,

CBDB,有包括一些人物基础信息,尤其籍贯、任官履历信息、社会网络信息等可参考。
对于一些不太常见的人物,可以在中国基本古籍库中搜索其信息,根据找到的史料,对其生平进行推测。还有一些人,属于地方性人物,也许找到对应的地方志文本,也许参考《爱如生方志库》等。
比如中华书局出版的《愧郯録》点校说明,对于作者岳珂的介绍:
愧郯録,南宋岳珂著。珂字肅之,號亦齋,又號倦齋,岳飛之孫,生於宋孝宗淳熙十年(一一八三),卒年約在理宗淳祐元年(一二四二)之後。歷任嘉興府知府、總領浙西江東財賦淮東軍馬錢糧、總領湖廣財賦、淮南江浙荆湖制置茶鹽使等職。岳珂稔熟典籍,學識淹博,歷官中外,長期在理財相關部門任職,兼具才學與吏幹。其編纂或自撰有九經三傳沿革例、鄂國金佗稡編續編、愧郯録、桯史、寶真齋法書贊、棠湖詩稿、玉楮詩稿等書
比如中华书局出版的《鹤林玉露》点校说明,对于作者羅大經的介绍:
羅大經字景綸,廬陵(今江西吉水縣)人。生平事跡不詳,我們祇知道他大約生於宋寧宗慶元初年,卒於宋理宗淳祐末年以後。少年時曾就讀於太學,嘉定十五年(一二二二)鄉試中舉,寶慶二年(一二二六)登進士第。此後曾做過容州(今廣西容縣)法曹掾、撫州(今江西撫州市)軍事推官等幾任相當於縣令的從八品小官。官於撫州時,由於受當時朝廷中一起矛盾紛争的牽累,被劾罷官。從此以後直到去世,就再也没有得以重返仕途。在幽雅恬静的山居中,完成了鶴林玉露的寫作。
最后,要说一下书籍ID。如同身份证有身份证号,书籍也有书籍ID。平台哪怕上传同一种的同一个版本,一个书并不会覆盖另外一个。实际上,平台中每一个书都有书籍的ID,默认是一长串的数字。当然我们也有专门的书籍ID的规范。为了便于统一管理,书籍ID由我们统一处理。老师们无须关心具体的书籍ID。
演示:举一个例子
作业:建立一条元数据
在平台中,元数据呈现如下图所示
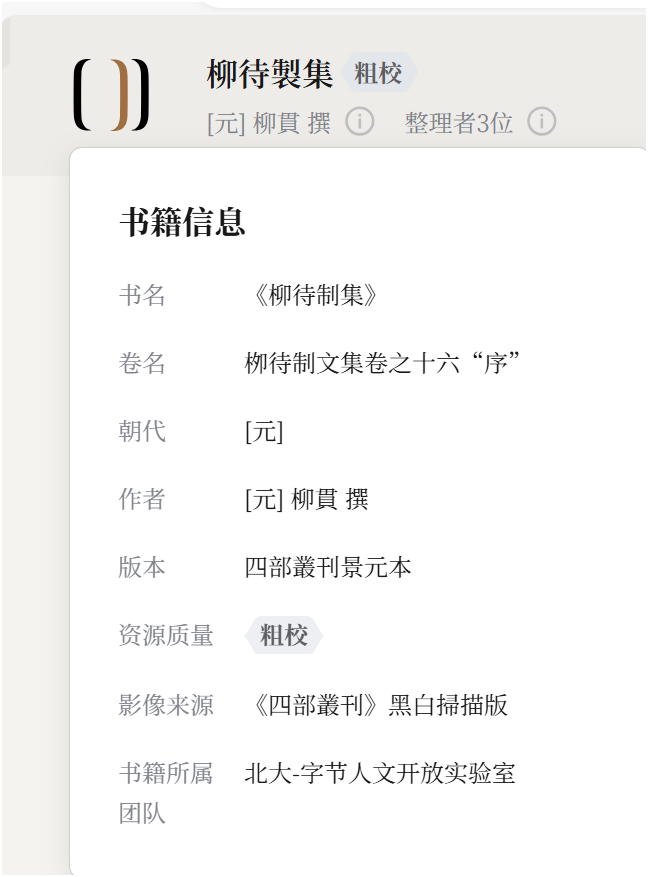
图中书名有误,“制”错成了“製造”的“製”,需要修改元数据。在书目管理元数据管理修改。
首先进入整理平台,搜索相关书目,然后就可以在“书目元数据”中进行修改

- 【转线下修改】数据准备(如何开始一本古籍的整理)
如何开始整理一本古籍?平台提供两种方式:1、单纯图片;2、图文数据。选择图片模式相当于从头开始进行完整的整理流程,而选择图文数据模式则可以从粗略的图文对照数据入手,甚至可以直接使用线下处理完成的成品。图文数据的处理较为复杂,需要通过代码进行清洗,并且不同来源的数据可能需要不同的处理代码。本文重点介绍从单纯图片开始的整理方法。
图像数据准备主要包括:整理图片数据并上传、分卷处理、上传参考文本。
- 图片数据
从哪里获得图像数据?
古籍整理平台上的图像数据主要有两种来源:一是开放获取(Open Access)资源,这些资源由各类公共图书馆机构提供,代表性的包括哈佛燕京图书馆、内阁文库等;二是影印出版资源,对于这些资源,可以通过自行扫描将纸质书籍中的古籍图像转化为数字格式。开放获取资源大多为彩色扫描,因此同一版本的古籍,应该优先选择开放获取资源。例如,哈佛燕京图书馆的古籍曾经影印出版,但大多数为黑白影印,且清晰度不如在线资源。
如何获取这些图像资源?
获取这些图像数据的途径有多种。首先,可以利用他人已经下载的资源,许多热心网友分享没有版权的古籍,提供各种开放资源供大家使用,典型的如书格网。其次,一些网友编写了下载工具,便于批量下载古籍资源。需要注意的是,使用爬虫软件时,要遵守相关法律法规以及网站的使用条款。
支持上传的图像格式:PNG、JPG、JPEG
PNG的特点:
- 无损压缩:PNG格式能够确保古籍图像在存储和传输过程中不会丢失任何细节和色彩信息。
- 透明背景:PNG格式支持图像透明背景,可以方便地将古籍图像放置在不同的背景上进行数字化展示。
JPG的特点:
- 节省存储空间:JPG格式通过压缩可以大大减少图像文件的大小,对于大量古籍图像的存储具有明显的优势。
- 广泛兼容:JPG格式几乎被所有图像查看软件、操作系统和设备支持。
- 有损压缩:JPG格式属于有损压缩格式,在压缩过程中,图像的细节和质量可能会有所损失。
拼版页面的切割
使用老马软件ComicEnhancerPro对拼版页面进行切割,切割后通常为筒子页。如果需要切割为单页,还需进一步操作。
操作步骤:
- 打开软件,选择“文件”菜单中的“打开”选项,加载要处理的拼版图像文件。
- 使用“切边”工具,将裁剪框的边缘拖动至拼版页面的中央,确保裁剪框准确地将页面从中间分开。
- 确认切分位置及参数无误后,点击“确定”按钮执行切分操作。建议先切割上半页,再切割下半页。
- 切割完成后,进行必要的改名操作。
针对PDF格式古籍的自动切图
虽然PDF格式本身不是图像格式,但可以将古籍图像以PDF格式封装,每一页代表一张图像页面。针对这类PDF古籍,可使用软件提取单种书籍内容,上传后平台可以自动切割为单页,或选择去除图像边缘的框线。
“PDF补补丁”从PDF中导出图像
使用“PDF补补丁”软件从PDF文件中无损导出图像:
- 在软件界面中选择“提取图片”功能。
- 选择需要提取图像的PDF文件。
- 默认情况下,程序会自动将图片输出至与输入文件同名的目录,也可以点击“输出图片位置”按钮指定导出位置。
- 点击“提取图片”按钮,等待软件将PDF中的图像提取到指定文件夹。
古籍AB页
对于古籍的刻本页面切分,通常以版心的中线作为切分线,将原有的半页分为单独的页面。版心右侧为页面A,版心左侧为页面B。对于扫描的图片,建议不要做过多修版处理,页面外的内容可适当裁剪。
古籍图片命名原则
古籍图片的命名遵循以下标准:
- 书目ID编号 + 卷次编号 + 页码编号
例如:SBCK0001_00004_00005A
- A. 书目ID号:每本书有唯一的特殊编号,不同书籍之间的ID不可混用。书目ID通常由字母和数字组成,字母部分一般为2到4个大写字母,数字部分根据情况为3到6位。
- B. 卷次编号:根据书籍内容的卷次进行切分,确保每卷的内容一致。卷次编号表示该卷在书中的次序。例如,序言单独切分时,其卷次编号为
00001,原书中的“卷一”在序言之后则为00002,以此类推。 - C. 页码编号:每页图像根据版心进行切分,版心右侧为A,版心左侧为B。页码编号以卷次编号为主,如图像位于第7卷第15页的B侧,则命名为:
00007_00015B。
例如,SBCK0001_00004_00005A 表示《四部丛刊》第一本《周易注》中的第四卷第5页的版心右侧页面。
上传至平台后,如果发现古籍图像顺序错乱,可进行图片的添加、删除或顺序调整等操作。
- 分卷
自动分卷与分卷原则
分卷工作内容概要 在系统自动分卷的基础上,针对不完善的部分进行人工调整和整理,具体包括:
- 删除错误的分卷;
- 更正错误的卷名;
- 补充遗漏的分卷;
- 删除空白页,如多余的封面、封底、衬页等。
二、分卷规范与格式说明
分卷的目的是将古籍按其原始结构拆分成自然可分割的多个部分,确保每一部分的字数处于适当范围,从而便于平台的整理与分发。需要特别注意的是,分卷应根据自然页面进行划分,不能在单一页面内进行拆分。
关于卷的类型,基于古籍的结构,我们将其视为由以下几部分顺序构成:
- 卷首
- 目录
- 前序
- 正文(包括一个或多个卷)
- 后跋
其中,每一部分都可以看作是一个独立的“卷”单位。以上几部分应严格按照顺序排列,但可能会缺少其中的某些部分。
以《朱子年谱》(清刊本)为例:

格式认定及相关说明
正文的认定 正文是古籍的主体部分,由独立单元或多个单元组成。每一个单元可以视为一卷,这里的“卷”可以理解为传统意义上的卷、章、回,或是相对独立的部分。
1-1. 正文分卷提示:每卷卷首开头提示 对于正文部分的分卷,是整个分卷工作中最为关键的环节之一。最常见的分卷提示出现在每卷的卷首,通常包括“卷上”、“卷下”、“卷中”、“卷一”、“卷之一”、“卷第一”等标识,示例如下:



1-2. 正文分卷提示二:书的版心 需要注意的是,有些典籍的卷首并未明确标示“卷”的信息。以《宋文文山先生全集》为例,正文每卷的开头并没有标明是第几卷。遇到这种情况时,我们可以通过前后页的内容、目录或该页版心中提供的信息来推断。以下图所示为例:

1-3. 正文分卷提示三:目录信息 以《西齋集》为例,依据该书的目录(图1、2),可以发现该书的分卷并未以“卷”作为标识,而是以“时日”为单位。正文的分卷也与目录中的分卷信息相一致(如图3、4)。因此,在进行该书分卷时,应结合目录中的信息,以“时日”作为分卷的依据,而分卷的题名应遵循目录中给出的方式,使用“时日”命名,而非传统的“XX卷”(如图5)。





1-4. 正文分卷提示四:全书结构 极少数典籍既没有目录,且各卷又没有明确的“卷”标识,版心提供的信息也不清晰。面对这种情况,最有效的处理方式是根据正文本身的结构进行分卷。此时需要深入研究书籍的整体结构与编排思路,通常按照书中的大标题来划分卷次。
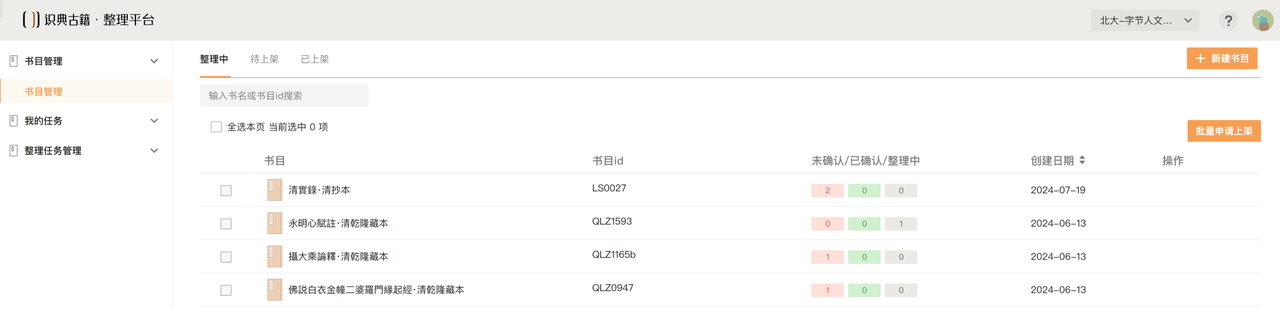
以《容台稿》为例,该书中“容台稿”、“符台稿”、“二台稿”这几个部分有明显的标题标识,因此可以推断该书由“容台稿”、“符台稿”、“二台稿”三个主要部分组成。根据这一结构,该书的正文应划分为三卷。


目录的认定
目录通常位于全书的前部,在正文之前。进行分卷时,目录应单独成卷,确保其独立存在。然而,某些典籍的目录可能与卷首或前序合并为一体,在这种情况下,目录可以与卷首或前序等部分一起作为一个整体进行分卷。


2-1. “目录-正文-目录-正文”的编排及其分卷方式 在某些典籍中,卷前有单独的目录,编排方式为“目录—正文—目录—正文”依次排列。对于这种情况,处理方式如下:
- 如果目录页数较少(仅几页),或者目录内容本身与卷的正文紧密相连,则可以将该卷的目录和正文一起划分为一卷,不必单独标出“目录”。
- 如果卷前的目录页数较多,并且目录是一个独立的单元,则可以将目录单独分割成一卷,例如“卷之二目录”,然后再接上“卷之二”正文。
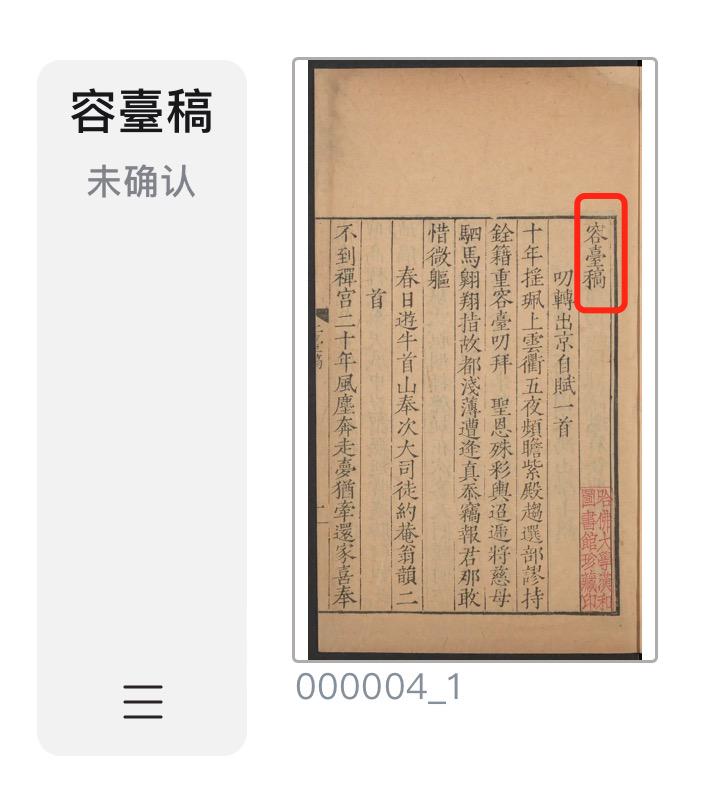
2-2. 目录本身又分为多个独立卷 对于像《太平御览》《书记洞诠》等典籍,由于其体系复杂、内容丰富、篇幅较长,正文之前的目录页数往往非常多。为了更好地处理这些庞大的目录内容,编著者通常将目录部分划分为多个独立的卷。遇到这种情况,应遵循原书的编排方式,将目录部分按照书中的划分分成多个目录卷。

卷首的认定 目录之前的内容被认定为“卷首”。如果目录是相对独立的,则卷首部分需要单独作为一卷。
前序的认定 目录与正文之间的部分称为“前序”。需要特别说明的是,命名为“前序”主要是为了方便分卷和切割,实际上该部分内容中不一定包含“序”字。在许多典籍中,目录之后直接进入正文,没有单独的“前序”部分。如果存在“前序”,则该部分应独立作为一卷。
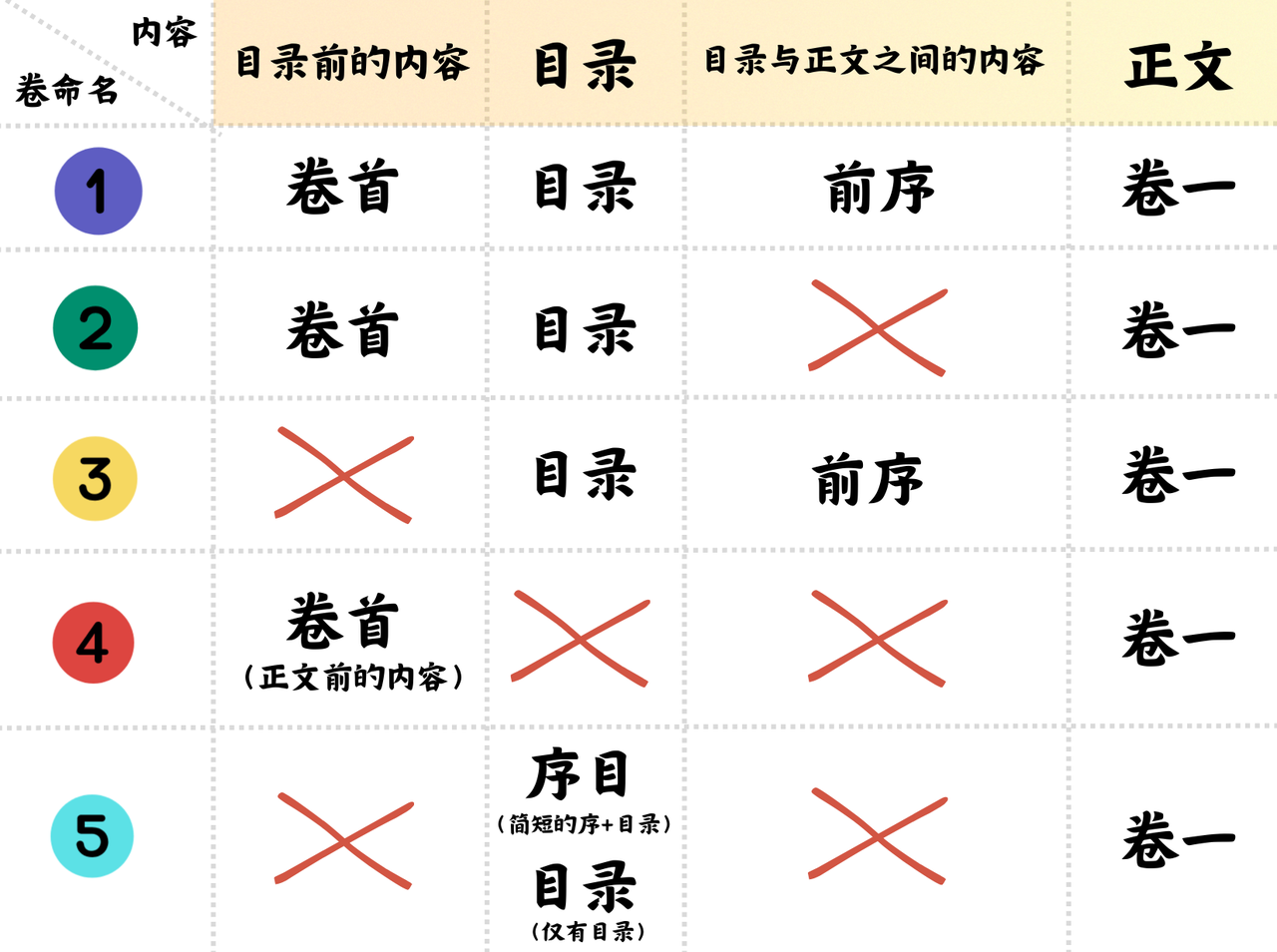
■补充:关于卷首、目录、前序、正文之间的命名方式 由于古籍体例较为复杂,以下图示可以简要概括各部分的命名和结构(X表示该部分内容缺失):
后跋的认定 正文之后的内容,无论是跋文、附记等其他文字,一律视为“后跋”,并单独成卷。如果书籍正文之后虽然没有明确的卷名,但内容较长且相对独立,则可以视为正文的一部分,按照卷的标准进行分割。
空白页的认定
- 封面页和封底页仅有书名,缺乏其他丰富信息的部分,应视为空白页并删除(如图1、2所示)。
- 分册的封面页、无文字的衬纸及空白页应视为空白页并删除(如图3)。 需要特别注意的是,虽然一些页面没有文字,但如果它们包含板框、栏线,并位于某一卷前或某一篇前,则不应视为空白页,应保留(如图4)。




三、分卷的题名方式
卷的名称准确反映其内容,而无需重复书名。
分卷完成后,需要根据实际内容情况编辑每卷的名称,即分卷题名。编辑方式如下:
- 将鼠标悬停在左侧的卷名上。
- 点击出现的“重命名”选项。
- 在弹出的框中输入新的卷名(如右图所示位置)。
需要特别说明的是,在为每卷命名时,以《茶史》一书为例,可以选择仅题写“卷首”、“目录”、“卷一”等,而不一定需要在在每个卷名中加入书名“茶史”。这样做的目的是简化命名,并确保每卷的名称准确反映其内容

如果一本书中包含多个独立的书籍,在进行分卷命名时,需要明确标识每本书的书名,以避免混淆。例如,可以采用以下命名方式:
- A书卷一
- A书卷二
- B书卷一
- C书卷一

四、识典平台分卷界面的按钮说明
识典平台的分卷界面中包含多个功能按钮,以下是几个常用按钮的详细介绍:
- 自动分卷 进入分卷页面后,首先点击“自动分卷”按钮,系统将自动进行初步的分卷操作。此过程可能需要一定时间。完成自动分卷后,用户可根据实际情况进行人工分卷调整。
- 插入分卷标 如果系统未自动进行分卷,或需要在某一处插入分卷标,可以点击该位置后的图片,再点击“插入分卷标”。此操作将手动添加分卷标记。
- 删除分卷标 如果系统错误地插入了分卷标,或某一位置不需要分卷标,可以点击该错误的分卷标,再点击“删除分卷标”进行删除。
- 编辑卷名称(即分卷题名) 要编辑卷名称,鼠标悬停在左侧的卷名上,点击“重命名”按钮,然后在弹出的框中输入新的卷名。
- 删除图片 若需删除空白页或不必要的图片,可以点击该图片,再点击“删除图片”按钮。需要注意的是,此操作不可撤销,请谨慎操作。
- 确认所有卷、确认当前卷 完成全书的分卷工作后,可以点击右上方的“确认所有卷”按钮,将整本典籍进入后续分发整理环节。
- 如果某一卷存在问题(如缺页、图片模糊或顺序错误等),则无法点击“确认所有卷”。此时,应点击“确认当前卷”按钮确认无问题的卷,对于存在问题的卷,保持“未确认”(红色)状态,等待进一步处理。
这些按钮帮助用户高效地完成分卷工作,确保每个环节都能准确无误地执行。
五、附:系统分卷的常见错误
- 书的分卷越多,自动分卷的效果越差。
- 会把卷末的信息识别为分卷

- 会把版心的信息识别为分卷,左右版心都可能被错误识别
- 左边的情况

- 右边的情况

- 版面模糊,无法自动识别

- 上传参考文本
本平台贯彻“比较”的思路,旨在吸收和利用现有的数字化成果。具体而言,参考文本包括文字和标点两部分,分别有其独特的作用。
为什么要上传文字参考? 如果某本书已有可获取的数字化文本,通常这些文本来自排印本,通过数据采集或OCR(光学字符识别)技术获取。将这些文本作为文字参考的校本,可以帮助我们校对两个不同来源的文本,从而有效提高文字的准确性。这种校对过程能够识别并修正文本中的错误,从而提升整体的数字化质量。
为什么要上传标点参考? 标点参考的重要性与文字参考类似。标点位置可能存在错误,特别是在不同版本的文本中,标点的使用往往会有所不同。通过比较同一文本的不同标点版本,可以发现并纠正标点的错误。标点的校本可以来自学界已有的标点成果,或基于其他标点模型的研究。实践表明,两个标点模型之间的差异往往会揭示标点错误的潜在位置,因此,利用这些差异有助于精确地修正标点错误。
通过上传文字和标点参考,平台能够提高文本校对的准确性,确保数字化古籍的质量和可靠性。
- 图文数据
如果已有图文数据,可以通过程序批量上传至平台。中间数据采用纯文本形式,这使得文件的合并与拆分变得非常简单。同时,中间数据具有较高的可读性,便于线下修改。与XML相比,中间数据更易于程序处理,能够直接以字符串的方式进行操作。这种特性使得数据转换和处理更加便捷,无需复杂的XML解析过程,处理速度更快,并且更容易避免潜在的错误。
样例:
1书籍编号、页码
卷前图片命名方式
[SBCK001_00001 00000A]
[SBCK001_00001 00000B]
[SBCK001_00001 00000C]
卷内图片命名方式
[书籍编号_卷编号 图片物理编号]
[SBCK001_00001 00001A]
图片命名方式
书籍编号_图片物理编号
SBCK001_00001_00001A.png
2标题
<vol>卷标题</vol>
<h1>一级标题</h1>
<h2>二级标题</h2>
<h3>三级标题</h3>
<h4>四级标题</h4>
<h5>五级标题</h5>
3目录无分段
目录用<toc></toc>括起来,中间内容不分段。如:
<toc>
目录内容
目录内容
目录内容
</toc>
4作者
作者一般位于书名之下,如:
书名书名
(作者|author)
5段落
在一段文字前用<p>隔开,表示后面文字为单独一段。如:
<p>段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字<p>段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字段落文字
6注文
用圆括号括注的内容表示为注文。如:
正文正文正文正文正文正文正文正文(注文注文注文注文注文)正文正文正文正文正文正文正文正文(注文注文注文注文注文)正文正文正文正文正文正文正文正文(注文注文注文注文注文)
7实体
{人名|peop}
{地点|tpn}
{书名|liter}
{时间|date}
{官名|offi}
{国家|country}
清洗成中间格式后,就可以用中间数据转xml的脚本
批量上传命令行,有API
演示:上传PDF文档,进行分卷
作业:发起一部书的整理
- 【转线下修改】文字识别
文字识别校对
我们想要古籍文字被正确地识别,就需要了解古籍的版式。
- 古籍版式
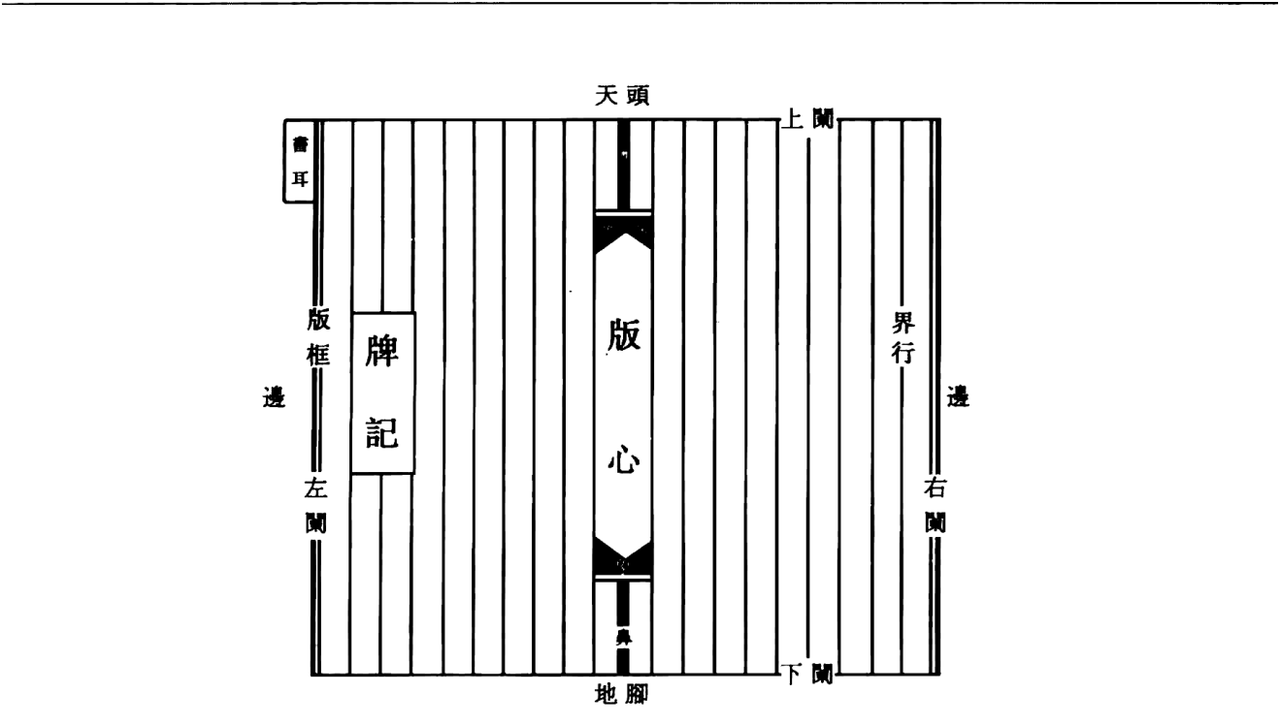
古籍装帧时沿其正中的中缝将书页对折成两页装订后,所见称为“半叶”,该区域转化为翻口。常刻书名、篇名、卷次、页次、刻书堂号、鱼尾、刻工名等,所记载信息是著录版本的重要依据。我们平台的古籍都是两页装订的,如下图所示(《玉茗堂诗集》)。

我们进行文字识别时,边内的文字,版心的文字也要删除。如下图标红部分要删除。
- 调整切分
平台上古籍计算机在处理切分文字时往往有误,可能有缺失,可能将一个字切分成两个字,可能将两个字识别成一个字。
- 删除多余文字
版心、天头、地脚的文字往往会被误切分,首先将版心、天头、地脚的文字都需要删除,然后再调整内部的字框。

上图页面文字调整如下

- 删除纸背文字
古籍纸张很薄,很多字迹会透过纸张,然后被误识别,这时需要删除全部字框。

- 删除带图文字
图中图片上的“楓”字删除。

- 调整顺序
许多古籍往往有注。隋唐时期,注文写成双行小字的格式已经成为定例。这样便于区分原文和注文,不易引起混乱。双行小注的出现,使书籍版面产生了文字的大小变化,并成为后世书籍版面的一个通则。平台在处理文本时,对于复杂的有双行小注的页面容易将顺序弄错,这时我们需要手动调整。(《六臣注文选》)如下图。

其正确的顺序如下,其中双行注释是从第一行底接下一行首。
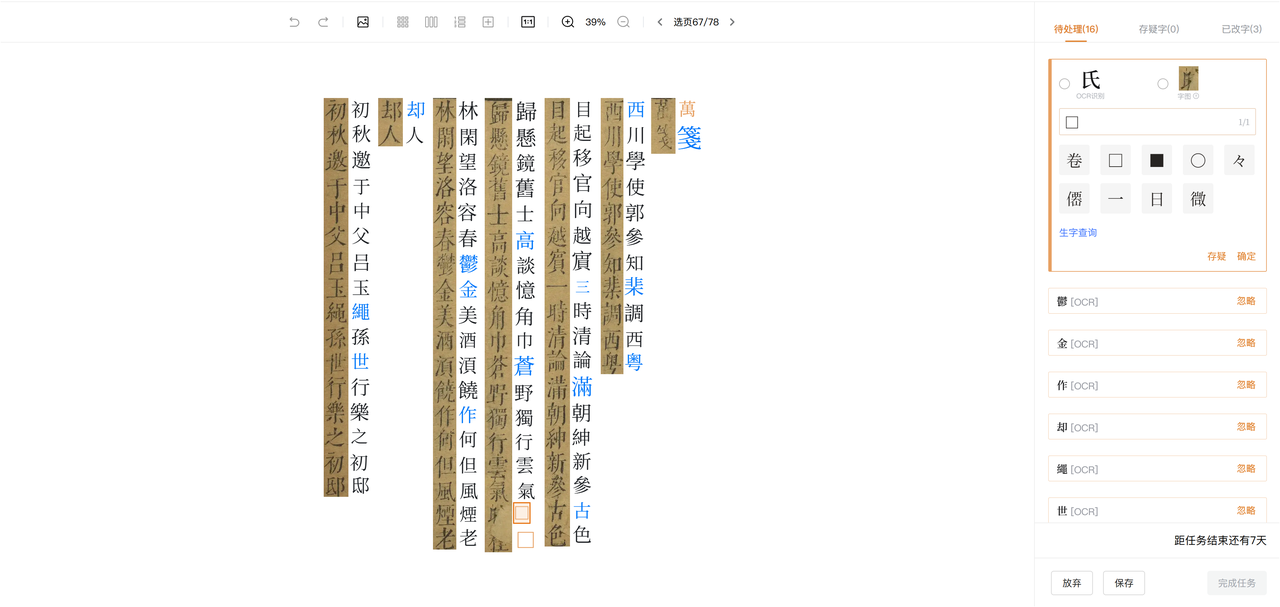
- 校对文字
调整号顺序之后,我们可以进入文字校对环节。平台会将OCR存疑字都列出来,并且旁边还有生字查询一栏,非常方便。
- 修改OCR识别错误文字
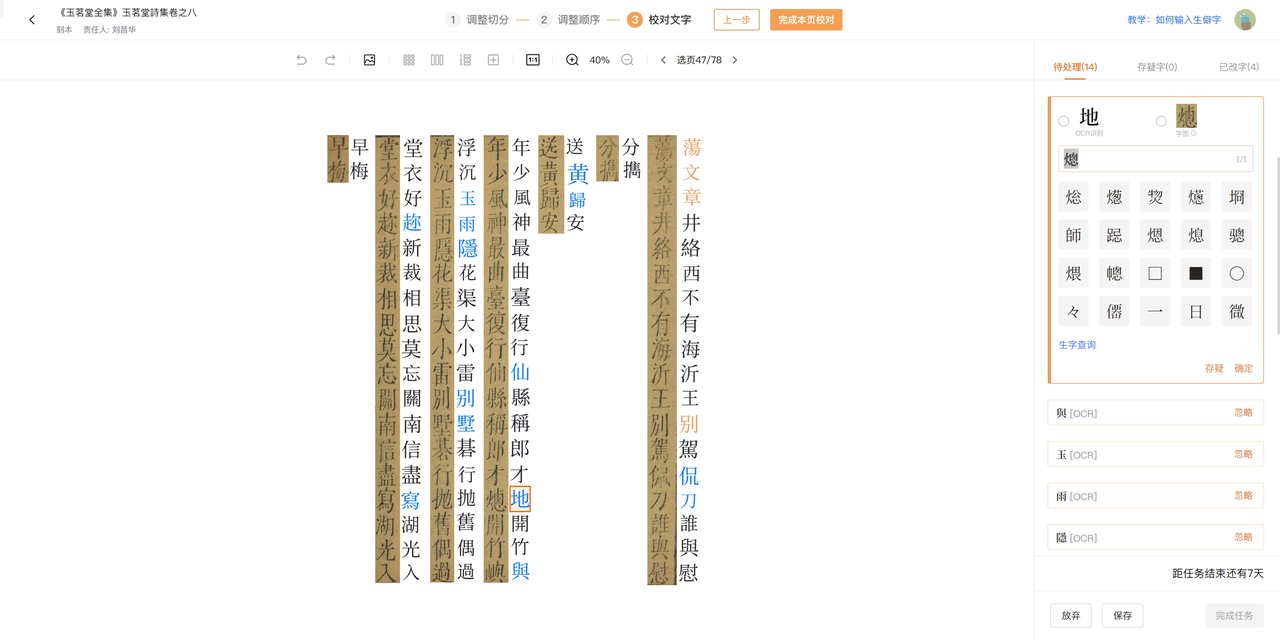
如下图中的“熜”被OCR成了“地”字,但备选框一栏还是列出了“熜”字。我们进行文字识别时,并不追求文字和原字形一模一样,只要是同一个字即可。假如备选框未列出正确的文字,我们可以参考下文的异体字查询的方法。
下图中的“玄”字错识别成“员”字了,而备选框没有,我们可以手动输入。

- 模糊不清文字识别
模糊不清的文字,可用虚缺号“□”代替,切记主观臆断。
如下图中“云气”后两个
- 【转线下修改】文字精校
文字校勘(讹脱衍倒)
校本上传
文字精校
版刻混用字
汉字编码
异体字原理、版刻混用字
字典查询、工具
- 确定规范文本
文字校勘的首要环节是形成规范的文本,没有规范的文本,校勘无从谈起。而形成规范的文本,首先要认字,正确地识别出古籍中的每一个字,然后将之转变成我们今天的规范繁体字。
- 版刻混用字
古代印刷术以雕版印刷术为主流,刻工刻版是计件工资,刻多少字多少钱。而很多字字形相似,刻工也不认识字,为了图快赚钱,就都刻成一样的。同时有些版刻后代反复印刷出现断版磨损,不少字就变成了另外一个字,如“天”变成“大”,“太”变成“大”。这些版刻混用字,平台都有提示,我们只需要根据平台的提示根据文义确定。下面附录版刻混用字表供大家进行参考。
暂时无法在飞书文档外展示此内容
- 生僻字、异体字
我国古籍浩如烟海,各个时期的各种写本、刻本用字极其复杂。虽然古代官方也颁布过一些规范的字书,但民间也并未遵循。直到近代,我们逐渐有了统一的汉字规范,并逐步推行,我们的汉字使用才基本统一。
古籍中的异体字具体大致可分为俗字和避讳字。
- 生僻字
生僻字是指古籍中罕见的汉字字形,如古方言用字,古代人名、地名、书名等用字,文字考辨中的例字等。因其有特定的含义,我们整理时必须保留原有字形。明显的错别字、死字(主要为非通行字书、韵书中因搜奇猎异而罗列的无用例、音义不全的汉字)不属于生僻字。
如图中的“濬”字属于生僻字,这种字需要保留原字。

- 俗字
俗字是与正字即当时官方字书如《康熙字典》规定的正字相对的汉字,这些字大多是平民百姓在民间使用,被认为是不合法、不合规的。不过正俗字是一对相对的概念,我们今天很多正字在古代的某一段时间是俗字,而今天的俗字在古代某一段时间可能是正字。对于俗字,我们如果能确定本字,则一律改回为本字。
- 避讳字
避讳是中国古代的一种特有的文化现象由于封建礼制、礼俗的规定约束,不敢直称尊长名字,以致讳用与尊长名同或仅音同的字。避讳般专指这种敬讳。如唐太宗名“世民”,唐修《晋书》《隋书》《南史》《北史》诸史,讳“世"为“代”,讳“民”作“人”。古人避讳有新造避讳字和代用避讳字两种。其中新造避讳字有缺笔字、变体字、异体字和合成字三种。代用避讳字则是用同音、同义、形近字代替。很多新造避讳字比较随意,但容易区分,且未被收入电脑字库中,在整理时,我们需要还原成本字。代用避讳字我们如果学力足够,也需要还原成本字。


如图中“元”字是避讳,当为“玄”字,“玄运”意为天命,我们可以在一旁校对单字,撰写校勘记。
- 异体字查询
- 汉字编码
在计算机时代,我们希望电脑能显示全世界所有的文字,于是世界各国的许多组织成立了统一码联盟(The Unicode Consortium),试图将每一个字赋予一个统一的编码(Unicode),而每一种不同的文字都位于一个编码区域。中日韩越国家都处于汉字文化圈,因此中日韩越区域的编码叫作中日韩统一表意文字(CJKV),又称作统汉码、统一汉字集(英语:Unihan),建立目的是将中、日、韩、越、壮、琉球文起源相同、本义相通、形状一样或稍异的表意文字,在ISO 10646及统一码标准赋予相同编码。这作业活动在统一码标准称为汉字等同。整理出来的中日韩统一表意文字,由统一码联盟建置的Unihan数据库维护。
全世界各地对文字研究的深入,不断有新发现的文字被编入Unicode中,Unicode每年更新,最新版为17.0,2024年发布。CJKV也不例外,CJKV也分为基本区、兼容区,然后不断新增汉字,编入拓展区,从拓展区A至拓展区I,共收录汉字97,681个。2024年发布的Unicode 17.0预计会公布拓展J区。我国最新的国家标准( GB 18030-2022)要求所有计算机支持基本区和A中的所有汉字(级别1),用于政务服务和公共服务的信息技术产品和信息系统应均需要支持到F区的汉字(级别3)。CJKV收录的汉字大部分来自古籍,少部分来自我国各少数民族的文字以及公安部门的人名、地名。
当然,汉字光有编码还不够,我们还需要有支持相应编码的字体。目前Windows、macOS系统自带的字体均能支持到F区的显示(级别3),iOS、Android则支持基本区(级别1)。当然对于我们进行古籍整理,字符集支持自然越大越好,对此我们需要添加超大字符集字体才能实现。目前支持到I区的字符集有开心宋体、天珩字库(http://cheonhyeong.com/Simplified/download.html,免费开源)、遍黑体(https://github.com/Fitzgerald-Porthmouth-Koenigsegg/Plangothic-Project,免费开源)。大家可以安装天珩字库、遍黑体,然后在Word、PhotoShop等软件中调用相应的字体,就可以显示全部编入Unicode的汉字。
- 异体字查询
- 字典查询
我们遇到异体字,可以使用一些网站进行查询.
- 首页 - 书同文汉字网
- zi.tools 字統网
- 字海网,叶典网:收字14万,囊括VsHx字海,康熙字典,汉语大字典,现代汉语词典,unicode系列全部汉字,成语词典,辞典,VsGo成语大字典,中华字海
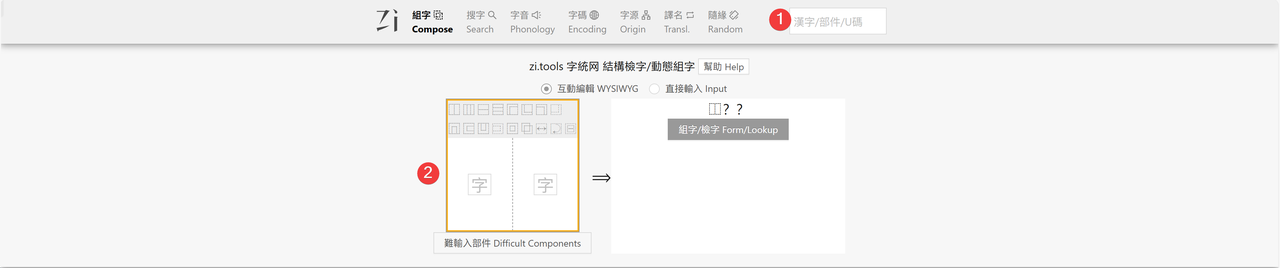
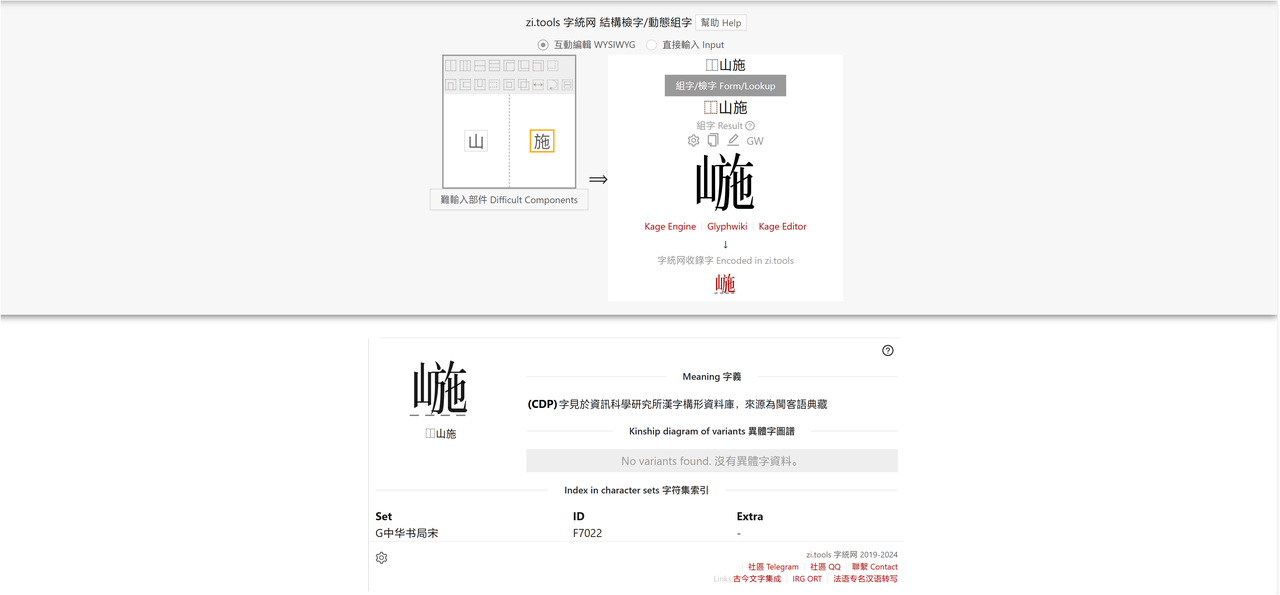
推荐优先使用字统网查询,字统网界面如下,我们可以直接在①中输入汉字、部件和Unicode编码,也可以在②中通过汉字部件组字,更精确地查询汉字。
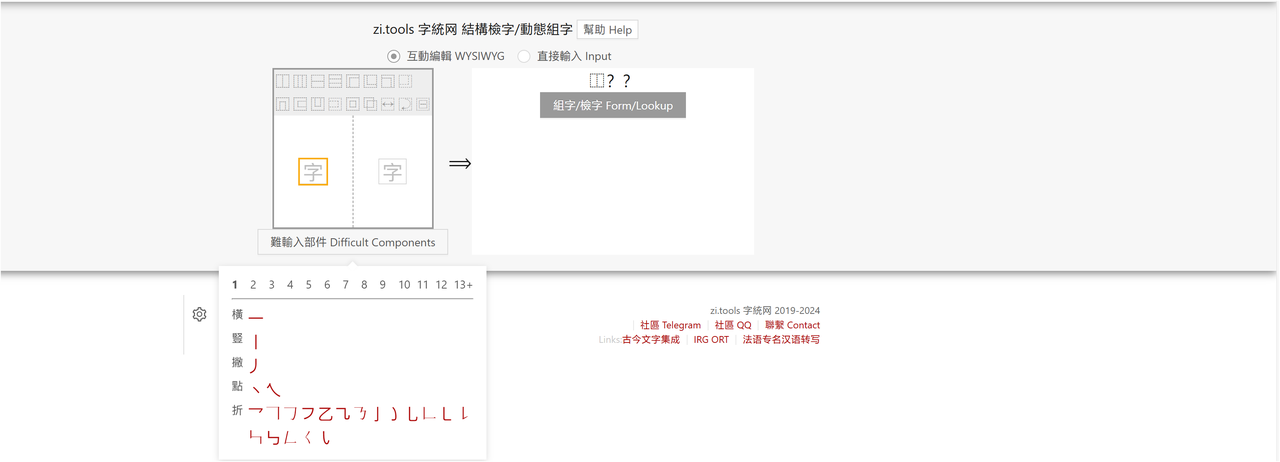
字统网组字还能通过选择难输入部件更方便地组字。

假如我们不认识下图的字,⿰山施,我们可以通过字统网查询,得知此字尚未收入Unicode中,这时需要使用字图。假如该字收入Unicode,则字统网可以直接复制粘贴该字。
如果我们需要进一步地追寻这个字是否有字书出自是什么意思,我们可以使用教育部《異體字字典》 臺灣學術網路十四版(正式七版)2024,不过由于网址在台湾,访问有点不稳定。
- 通过前后文查询
许多古籍耳熟能详,前人已有整理,我们还可以通过检索相应前后文句的方法确定不认识的异体字。最简单的我们可以直接百度搜索文句确定。不过百度上的许多文本准确度不太高。对此,我们还需要参考一些准确度更高的数据库。在校学生可以使用中华经典古籍库、汇典网等国内顶级古籍出版社的整理本文本确定。不过平台上很多书并未有整理本,那么我们还可以参考该书在erDataBases等数据库中的其他版本的文字确定。
其他网站如中國哲學書電子化計劃、中华典藏文本也主要是OCR文本,文本质量并不高于平台的OCR文本,智能略作参考。
- 异体字使用规范
对于生僻字,如古方言用字,古代人名、地名、书名等用字,文字考辨中的例字等均予以保留。避讳字一律改回本字。对于文中出现的无关文义的俗字均改回正字。出现Unicode中未收入的汉字,不影响文义的,均改回正字,便于阅读。
- 汉字字形
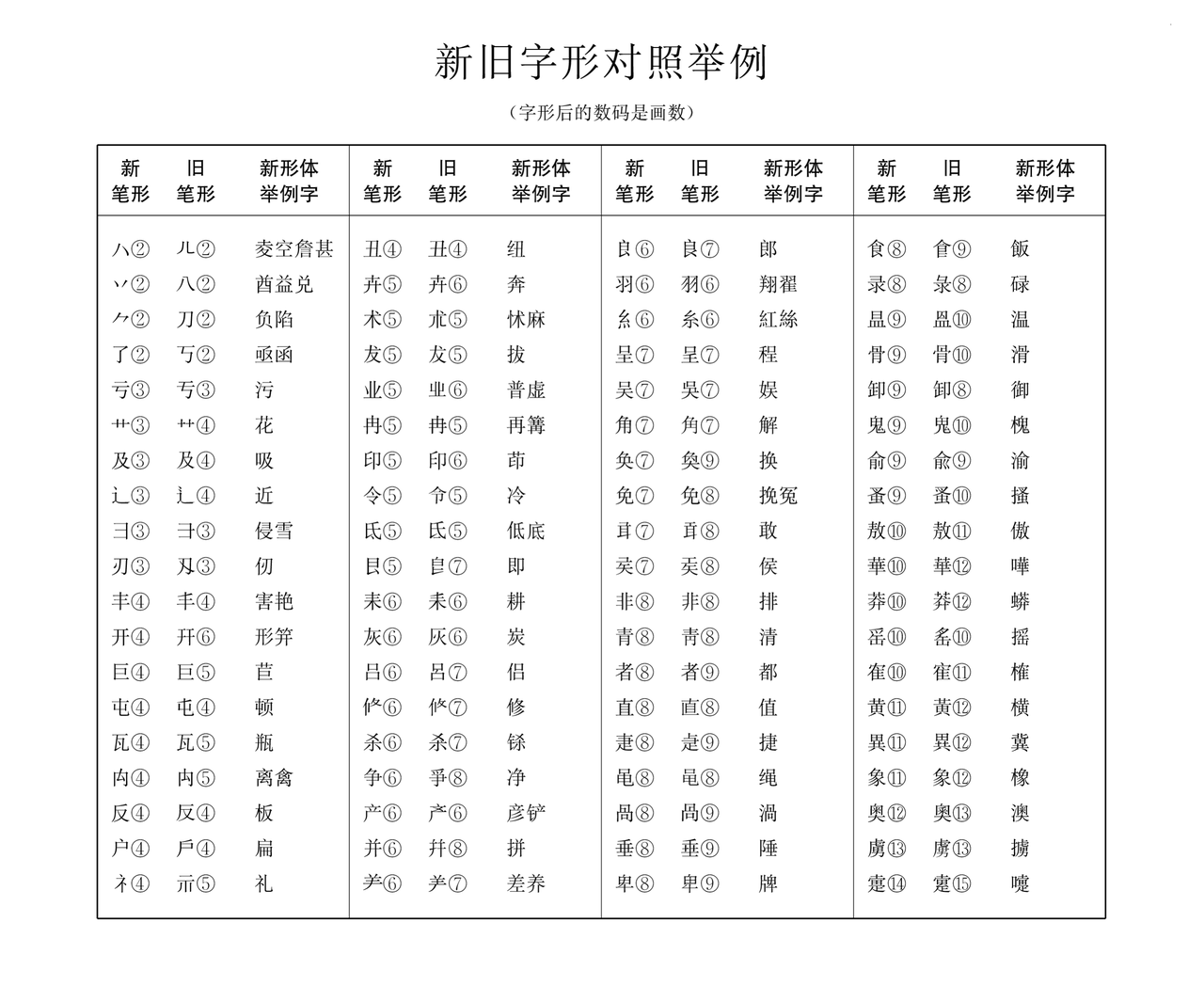
不论是中国大陆还是台湾,都曾调整印刷汉字字形,使它变成楷体的笔形。大家把整形后的写法称为“新字形”,无论繁体字还是简化字,均会套用“新字形”标准。大陆最先的“新字形”标准,可追溯至1965年出版的《印刷通用汉字字形表》。台湾则于1982年颁布了《常用国字标准字体表》。
而相对的“传承字形”或“传承印刷字形”,通称作“旧字形”,则指未向手写体靠拢、未整形之写法。这些字形,与《康熙》、《说文》、《辞海》、《大汉和》等由文字学者主导的传统字形规范吻合,一方面较能保存汉字字源或字理,另一方面也比较美观、比较适合版面排印的需求。
古籍刻本上的字体字形均是“旧字形”,和我们今天在日常生活中使用的汉字字形有一定的区别。我们可以参照下面这张图片,了解许多笔形的对应关系,这样我们就不必过多纠结于汉字的字形是否一致,节省时间。
具体相关的字形学理关系可参考下面文档
暂时无法在飞书文档外展示此内容
- 文字漫漶不清
古籍很多时候可能由于各种原因漫漶不清,对于这些文字,我们可以通过在数据库中检索上下文确定具体的问题。如果在数据库中也检索不到相应的文字,我们就使用虚缺号“□”标记相应缺字。
- 文字校勘
- 文字校勘
我们有了规范文本之后,就可以进行校勘了。
文献学上的校勘亦称“校雠”、“校订”。指综合运用多种文献资料(如该作品的不同版本以及上下文、相关语文材料、出土文献、图像资料等),比勘书本的文字与篇章,审定文本的正误。有对校、本校、他校和理校四种方法。条列校勘中所发现的相异情况的文字,称“校勘记”。
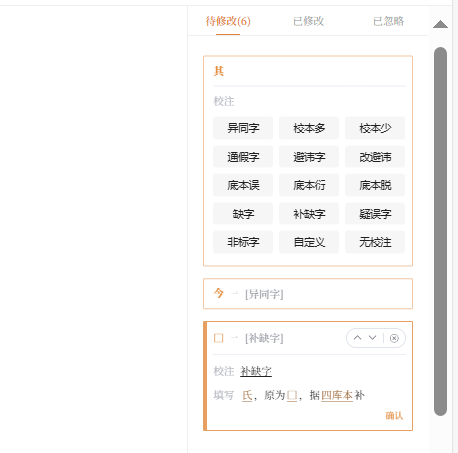
我们得到的规范文本即是我们的底本。平台上有多套与我们底本不同版本的文本作为校本,对于相异的文字,用类似Word批注的形式显示校对卡片。对于每个校对卡片,您可以选择这个地方正确的文字是什么并加以确认。确认后的卡片,也可以在「已修改」或者「已忽略」处找回。如下图所示。我们也可以借用校本确定一些不确定的异体字。


除此之外,我们选中文字、点击“校对单字“后,右侧评注区将出现菜单,可以选择出不同类型的校记(或者选择不出校记)。系统提供的校记类型如图所示,有
- 异同字:底本和校本有不同,但都能读得通。会出「某字,某本作某」这样的校记
- 校本多:校本在之后有其他字,会出「某字下,某本有某」这样的校记
- 校本少:校本没有这个字。会出「某字,某本无」这样的校记
- 疑误字:可以肯定某处有误字,但是不改字。会出「某字,据某本/文义当作某」这样的校记
- 通假字、避讳字,如名
- 缺字:对于黑白块(“□”|“■”)、空格等情形,可以使用缺字校注
- 自定义:可以自己书写任意校注;最多500个字
整理好文本后,我们就能进入下一步文本标点的环节。
- 结构整理
自动标点、自动分段
标题
分段(提顶、古籍中原有分段、古籍中没有分段。对话体、诗歌体)
结构整理时已经有自动标点。
平台文本均有经过AI处理过的自动标点,并且通过标点比对,对于有疑问的标点也有提示。我们可以对照许多文本的整理本,查阅相关辞书进行进一步的标点。
- 古籍标题排列
平台中将标题按类分为卷、篇、章、节、小节,整理者不需要纠结这些名词是否贴合古籍的本来分类,将之视作类似Word中的一级标题、二级标题,以此类推即可。

以下图为例,图中“新刻宋文丞相信國公文山先生全集卷之十二”是卷名,。“乐语”是一种文体,为对偶韵文,后附以诗,也有不附的。显然,本书是以按文体分类,这一卷有“乐语”自然也会有其他问题,“乐语”在书中也另起一行,那么可以作为“篇”。其余如荆南安之訂譌这些文字是刊刻信息,作为正文即可。“宴交代寧國孟知府致語”是篇名,我们依次作为“章”名就行了。

又如下图,图中“柳待制文集卷之五”为卷,“律詩”为篇,“七言”为章,“奉同伯庸應奉韵送伯生愽士行祠西嶽因入蜀朢祭河源二首”为节,依次类推。

- 古籍提顶不空行空格
古籍中出现“圣”“上”“天”“帝”“天子”“御”“大驾”“王”“诏”等涉及皇帝名讳的往往另起一行提顶,整理时不要另外分段。如图中,标题是“八月二日大駕北廵将校獵于𣪚不刺詔免漢官扈從南旋有期喜而成詠”,并非标题是“八月二日”,“大駕北廵将校獵于𣪚不刺詔免漢官扈從南旋有期喜而成詠”是注释。



- 古籍的注文与正文分离
- 标出注文
古籍的注文和原文联系紧密,不应该分开,单独成行。标题注文不要分离。注文为双行小注,有明显的标志。


- 识别标错为注文的正文
平台中有一些正文被误识别为正文,这时需要改回正文。


图中“規模靜觀時仁意無”明显是正文,平台自动识别成注文了,这时需要改成正文,否则读者隐藏注文去阅读文本就不通顺。
- 古籍分段
后面的铭文另外分段。


- 标点校对
標點符號用法共列出十六種符號,有句號(。)、問號(?)、嘆號(!)、逗號(,)、頓號(、)、分號(;)、冒號(:)、引號(“”‘’)、括號(〔〕等)、破折號(——)、省略號(……)、着重號、連接號(—)、間隔號(·)、書名號(《》)、專名號,標點古籍通常只使用其中的十三種,省略號、着重號、連接號一般不用。
- 标点的使用
古籍中标点一般多使用逗号、句号,平台上古籍也不使用括号,括号用于表明行文中注释性文字和校改文字,破折号也很少使用。注文不使用引号、书名号,凡书名、人名、地名等都使用实体标记的专名号。
- 如何标点
- 根据韵脚确定标点
古代的诗词曲赋铭文都要押韵。对于较难读懂的赋,押韵可以作为标点的依据。

- 句号使用
注文为完整句子时使用句号。

- 特殊符号的使用
- 墨钉符号的使用
古书中墨钉表示涂改,古人在古籍印刷或校勘过程中,遇到不清楚、不能确定的字,或遇到有夺文,而不能确定夺文是什么字的时候,就用“■”来表示,每个“■”表示一个字。“■”就叫“墨钉”。对此,我们遵照原文,不使用虚缺号“□”而使用“■”。



- 缺文使用虚缺号“□”。

如图中,“承”和“旨”之间有缺文,这时要添加虚缺号“□”。
- 实体校对
识典古籍中的人、时、地、书名、职官都属于实体,AI已经自动标注了实体,并链接到了相应的辞书百科。但是AI难免有错在,这时就需要进行实体校对。
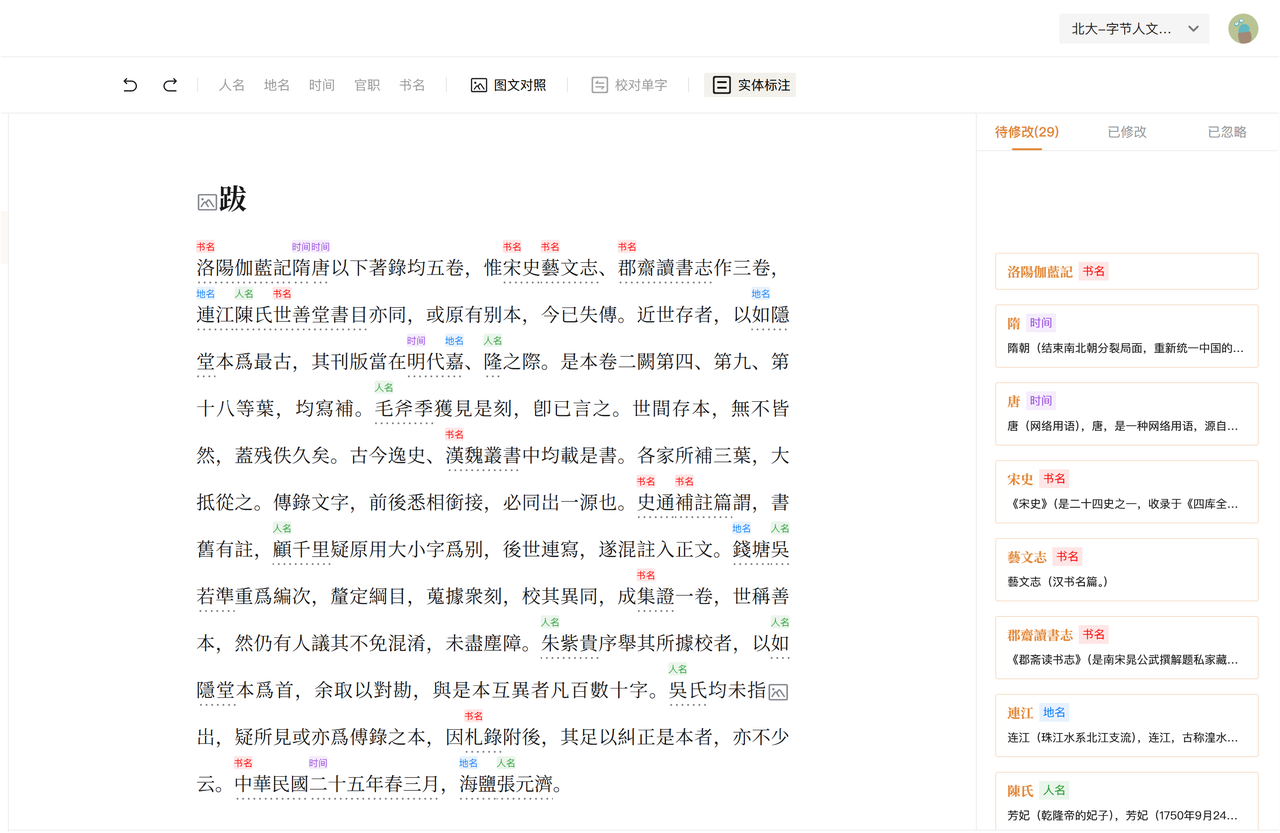
如图中,“唐”对应实体不对,我们可以点击旁边的小卡片,将它改为

《古今逸史》是书名没有添加实体,需要补上。

对于实体的对应关系,我们可能也不太熟悉能一一确定,对此我们可以参考下列工具性网站。
人名可以查CBDB,历代人物
地名可以查阅中国历史地理信息平台
书名可以查阅gj.library.sh.cn
职官可以查阅历史官职_中国历史官制大全_历史官职百科_历史职官大辞典
除此之外,也可以参考现有整理成果。
- 译文改写
我们平台AI的自动翻译大体上准确度已经很高了,但在细节上还有一些问题。这时需要我们人工改写。
译文改写的首要原则是准确,然后尽量让句子符合现代汉语表达。
以下列这段文字为例

- 改正错误翻译
译文中的《宋志》显然不是《宋史·艺文志》,核查文献这出自《宋史·礼志》,这时需要改成《宋史·礼志》。

又如上文的“委曲详尽”,自动翻译成曲折详尽,表述有点奇怪。我们查一下词典,可知,“曲折”就是详尽的意思。

- 专有名词不翻译
文中的“车驾宿大庆殿仪、驾宿太庙奉神主出室仪、驾诣青城斋宫仪”都是祭祀礼仪,不必翻译。
- 理顺文意
上文中《宋志》记载的“南郊仪注”表述也很奇怪,其实是《宋志》对“南郊仪”的注释,那就改为《宋志》对“南郊仪”的注释。